

Few Steps to Fast Redshift
Do you think a web dashboard which communicates directly with Amazon Redshift and shows tables, charts, numbers - statistics in general,can work well? We believe it can, as long as the dashboard is used by a few users. As this was our case, we have decided to give it a go.
As we were developing the dashboard, adding more statistics, more details and more features, it was getting slower and slower. And then the day came and a task „improving performance“ appeared and so did doubts if the web page and Redshift could work together efficiently.
The first thought was to add another layer as OLAP cubes built on top of Redshift or as a row database with the most recent data. Surprisingly enough, my research showed that people actually do build efficient dashboards directly speaking with Redshift, without any intermediate layer. The key is a proper design of the database taking the best of Redshift.
In this blog post I will tell you what I have done to significantly improve the system performance. In general I have taken three steps:
- adding a pre-aggregated table with the most often queried data,
- choosing dist key and sort key for the table,
- applying other little improvements.
First let‘s see how it all has looked before. We use Kimball Start Schema with two fact tables and several dimension tables. Each of dimension tables has a surrogate key as a primary key and a natural key as a property. Among other advantages tracking of historical data and different events stored in separate tables are worth mentioning.
The main problems of slow queries were:
- union of the two fact tables to show most of the statistics,
- latest name needed which required use of window functions or multiple joining of the same table while grouping by a natural key of a dimension table,
- each dimension‘s natural key appears in WHERE as well as GROUP BY clauses.
Pre-aggregated table
The pre-aggregated table is a very primitive form of a data mart, but good enough in my case. The main features of the table:
- data taken from both fact tables with a column to distinguish the data – no UNION needed,
- data aggregated to ensure the minimal needed granularity,
- the latest names of dimensions elements are included – no window functions needed. This step ensured performance improvement of about 50%. It sounds nice, doesn‘t it? Are there any disadvantages of such a solution? Surely – the storage usage. The pre-aggregated table uses 10% of the whole Redshift tables storage. Is it much? It depends. Our database is still far below any storage thresholds so it is perfectly acceptable in my case.
Distribution style and key
Following Amazon‘s instructions: Choose a column with high cardinality in the filtered result set., it was rather obvious to choose the date of the event as a distribution key as there is only one table and no joins are needed.
Sort key
One can decide between a compound sort key and an interleaved sort key and choose one or more columns to compose the key. This is best described in Amazon‘s dosc.
A compound key is made up of all of the columns listed in the sort key definition, in the order they are listed. A compound sort key is most useful when a query's filter applies conditions, such as filters and joins, that use a prefix of the sort keys. The performance benefits of compound sorting decrease when queries depend only on secondary sort columns, without referencing the primary columns. COMPOUND is the default sort type. An interleaved sort gives equal weight to each column, or subset of columns, in the sort key. If multiple queries use different columns for filters, then you can often improve performance for those queries by using an interleaved sort style. When a query uses restrictive predicates on secondary sort columns, interleaved sorting significantly improves query performance as compared to compound sorting.Although Amazon‘s documentation is a good source of knowledge, if you really want to understand the idea behind interleaved and compound sort keys, read this great two-parts article
Keeping all this in mind, I have decided to try out two different approaches:
- the date as a sort key – it is the only column to appear in each and every query,
- interleaved sort key composed of date and a two columns most often appearing in WHERE clause.
I have run a batch of queries (90 sets of 10 queries used by a dashboard with different WHERE clauses) against tables with sort keys defined as above. Here are the results:
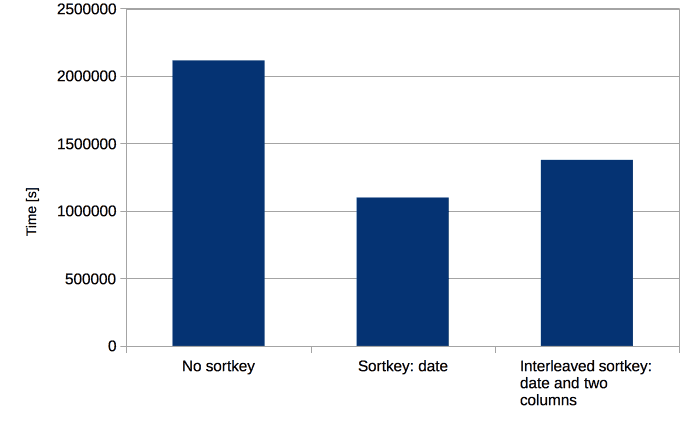
The simplest solution has turned out to be the best one. It gives about 50% better performance than no sort key and 20% better than the interleaved sort key.
Other little things
Another article that has helped me a lot comes from AWS big data blog and describes ten performance tuning techniques.
I was already familiar with most of the tips and only two were applying to my case. Nevertheless, it is a great article pointing out important improvements accompanied by instructions how to check if you need them and apply them if so.
The issues I have found useful in my case: Incorrect column encoding (Issue #1) – following the instructions I have applied the proper columns encoding. Tables with very large VARCHAR columns (Issue #5) – all VARCHAR columns had the default length of 256B while effectively the longest column needed not more than 50B and about half of the columns were shorter than 10B.
Summary
Applying all above mentioned improvements has made the system over 80% faster than before. Shall I be proud of myself for such a great improvement or rather blame myself for not applying all these while designing the database? I personally believe there are things you cannot foresee and development is a process of designing, implementing and continuous improving.