

webfrontendbackend
7 min
How does the web work - simplified
Very often, when recruiting for a frontend/backend/fullstack developer, especially for junior positions, the question is asked - how is it actually that in the browser somebody enters a specific address and a website related to it appears? This question is good because it allows the recruiter to test knowledge from many fields at once by asking deeper into the topic, while the candidate answers. So let's try to provide a model answer to this type of question and attempt to predict a few additional questions from the recruiter during the answer to the original question.

Before we start answering, let's make some assumptions, which are essential to get the answer started:
- The computer is equipped with a browser, which is a program designed to view and download resources made available by web servers.
- The computer is connected via a router/modem to an Internet service provider (ISP).
Our answer can be written as a sequence of steps that are performed in order:
- You enter the URL in the web browser,
- The entered URL address is translated into an IP address,
- The web browser sends an HTTP request to the provided IP address
- The server sends an HTTP response to the browser
- The browser starts rendering the resulting HTML based on the received HTTP response.
Now let's move on to the details of the individual steps:
-
This step is self-explanatory. We just type the URL into the address bar of the browser - nothing easier!
-
The address we entered in the previous step is easy for a human to remember, but machines do not use such names. They use IP addresses (short for Internet Protocol Address), and an identification number is given to computers or other devices that connect to the network, which allows them to communicate properly. In the decimal system, it is written with 4 numbers from the range 0-255 separated by periods (eg 77.55.142.42). Changing a human-readable address to a numeric form occurs through the DNS (Domain Name System). DNS works like a phone book that assigns IP addresses to specific domain names. It is a huge database of records that are used by users all over the world. It is worth mentioning that first the browser's DNS cache is checked, then our operating system's DNS cache, and finally the DNS provided by the ISP.
-
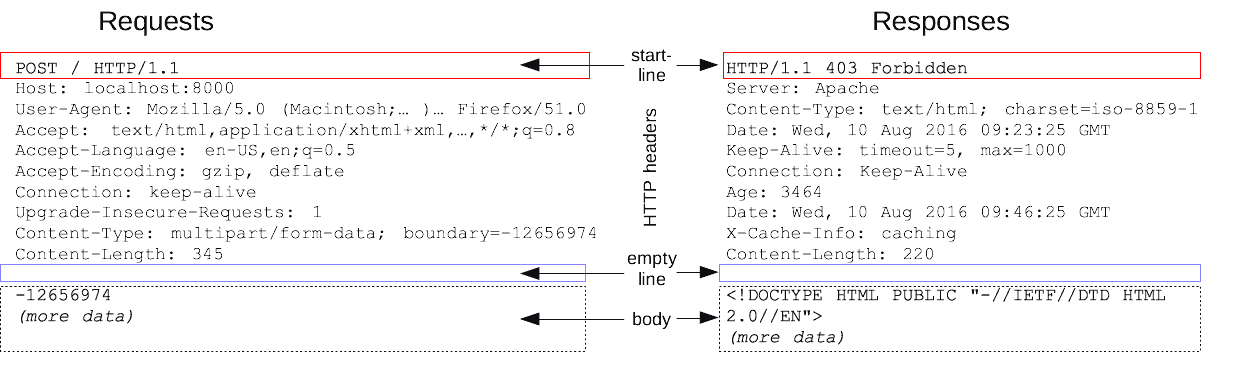
To be able to send an HTTP request from the browser to the server, it is necessary to establish a connection between them. This is done using the TCP protocol. The connection is initiated by the browser, followed by a three-way handshake, after which the browser and the client are ready to transmit and receive the transmitted data. This is where the question may arise - what is the difference between the TCP protocol and UDP protocol. From the perspective of a web application developer, a simple comparison is enough. UDP is faster, simpler, and more efficient than TCP, but it does not guarantee the delivery of all data packets. TCP will resend it if any data packet is not delivered. The data is transferred using the HTTP protocols - this means that they have a specific structure. The HTTP protocol consists of exactly the following parts:
- the first one specifies the HTTP method we use, the resource on the server side, and the protocol version,
- the second part contains the headers we use,
- the third is empty :)
- the fourth is the body of the message (if any).
There are 9 HTTP methods we can use. I will not describe them all here because they are well described on the MDN website. Often, a trick question may be how the PATCH method differs from the PUT method. A correctly implemented PUT method is one that can be performed N times and its result will always be the same - such methods are called idempotent. The PATCH method does not guarantee this.Body is the optional part because requests fetching resources, like GET, HEAD, DELETE, or OPTIONS, usually don't need one. Some requests send data to the server in order to update it: as often the case with POST, PUT, and PATCH requests.
Bodies can be broadly divided into two categories:
- single-resource bodies, consisting of one single file
- multiple-resource bodies, consisting of a multipart body, each containing a different bit of information.
-
The server replies to us with a message consisting of 4 parts containing:
- protocol version, HTTP code, and HTTP message
- headers
- a blank line again
- body of the message (if any)
At this point, it is worth briefly talking about the possible HTTP codes. They belong to five basic groups:
Informational responses (100–199)
Successful responses (200–299)
Redirection messages (300–399)
Client error responses (400–499)
Server error responses (500–599)When creating a REST API, we most often use 200, 201, 204, 400, 401, 403, 404, 409, 500 - it is worth knowing what these statuses are characterized by and when to use them, this question will surely be asked. In order to learn more about the statuses, I refer you here.
-
The browser receives the bytes of data, but it can’t really do anything with it; the raw bytes of data must be converted to a form it understands. First, the raw bytes of data are converted into characters. This conversion is done based on the character encoding of the HTML file. These characters are further parsed into something called tokens. When you save a file with the .html extension, you signal to the browser engine to interpret the file as an HTML document. The way the browser interprets this file is by first parsing it. In the parsing process, and particularly during tokenization, every start and end HTML tag in the file is accounted for. The parser understands each string in angle brackets (e.g
<html>) and understands the set of rules that apply to each of them. For example, a token that represents an anchor tag will have different properties from one that represents a paragraph token. After the tokenization is done, the tokens are then converted into nodes. You may think of nodes as separate entities within the document object tree. Upon creating these nodes, the nodes are then linked in a tree data structure known as the DOM. The DOM establishes the parent-child relationships, adjacent sibling relationships, etc. The relationship between every node is established in this DOM object.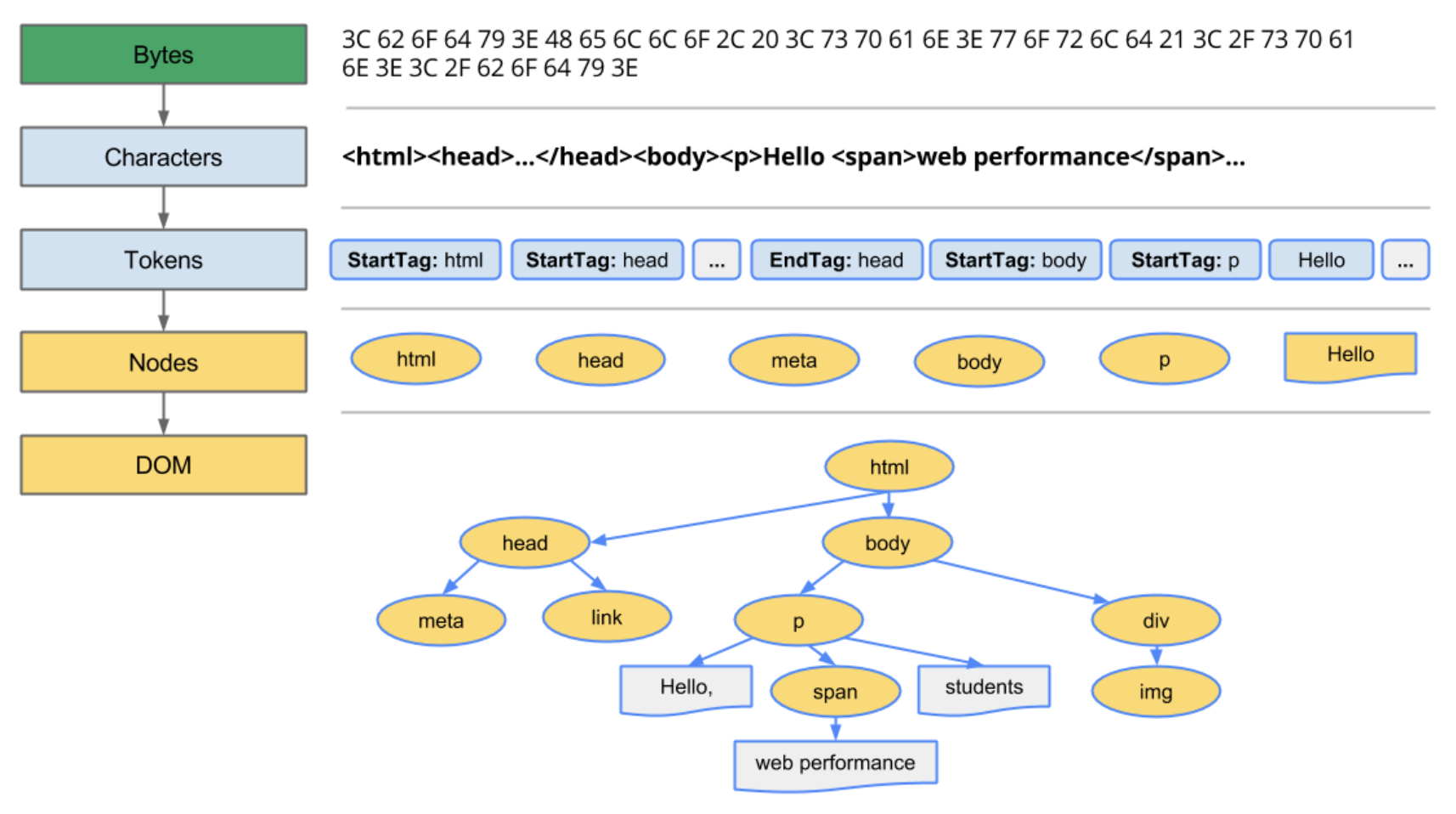
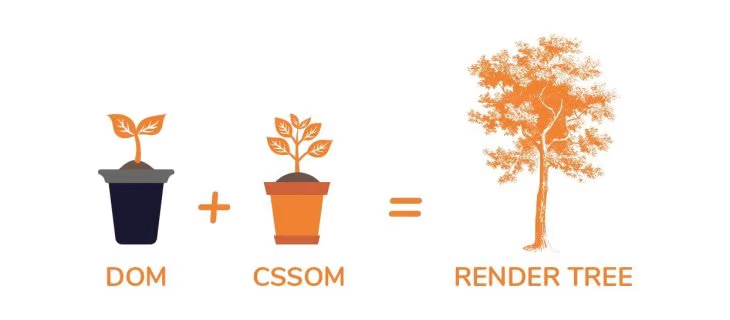
The exact same thing happens with styles related to the document from bytes threw characters, tokens, and nodes they end up forming a CSSOM.The DOM and CSSOM tree structures are two independent structures. The DOM contains all the information about the page’s HTML element’s relationships, while the CSSOM contains information on how the elements are styled. The browser combines the DOM and CSSOM trees into a render tree. The render tree contains information on all visible DOM content on the page and all the required CSSOM information for the different nodes. Note that if an element has been hidden by CSS (e.g., by using
display: none), the node will not be represented in the render tree.
With the render tree constructed, the next step is to perform the layout. Right now, we have the content and style information of all visible content on the screen, but we haven’t actually rendered anything to the screen. The browser has to calculate the exact size and position of each object on the page. With the information on the content (DOM), style (CSSOM), and the exact layout of the elements computed, the browser now “paints” the individual node on the screen. Finally, the elements are now rendered to the screen!