

androidjavakotlinbenchmark
5 min
Microbenchmarking on Android
Since Kotlin becomes more and more popular, especially amongst Android developers (and it's officially supported by Google), some people decided to compare its runtime performance with Java. After reading a few articles I wanted to test it myself and now I'm ready to share some of my observations and experiences.
What is it about?
Microbenchmarking is just micro-scale benchmarking :-) It's about measuring the performance of something really "small" that may take just micro- or nanoseconds, like calling a function or iterating over a collection.
I really recommend to read this wiki page on GitHub as it summarizes a few very important aspects of microbenchmarking, including its fallibility and some possible reasons why you could ever consider doing it. It also explains why you should actually avoid writing microbenchmarks as there are only a few reasonable excuses for doing it (mostly when you develop a performance-critical library or framework).

How do I start?
Writing a microbenchmark can be as simple as running some piece of code in a loop and measuring the time. You can also use one of the existing frameworks which have some useful features like the possibility to easily configure the way your benchmarks will be executed.
Unfortunately, if you are willing to perform the tests on Android, you can't use probably the most advanced library, JMH, as it uses some part of the Java API not available in Android API. This fact might discourage you from using Android platform for your benchmarks but you should bear in mind ART and Dalvik have significantly different characteristics from the JVM so optimizing code for JVM may be pessimizing it for Android (take a look at this commit in Gson library).
Manual measurements
The simplest way to measure the execution time of some code block is to call it large number of times in a loop like below:
fun measure() {
val reps: Long = 1_000_000
var sum: Long = 0L
val callFuncBegin = System.nanoTime()
for (i in 0 until reps) {
sum += addConst(i)
}
val callFuncEnd = System.nanoTime()
val callFuncDiff = Math.abs(callFuncEnd - callFuncBegin)
println(sum)
val result = callFuncDiff / reps
println(result)
}
fun addConst(number: Long): Long {
return 5 + number
}
In this example we benchmark the addConst function. If you are new to microbenchmarking, I bet you have a few questions.
First of all, we need multiple addConst calls for a few reasons, for example because System.nanoTime() doesn't really need to be that accurate as you might think. The documentation says it clearly:
This method provides nanosecond precision, but not necessarily nanosecond resolution (that is, how frequently the value changes) - no guarantees are made except that the resolution is at least as good as that of currentTimeMillis().
Another reason is to get more confident results as the test environment (the smartphone) is very complex and it surely will take different amount of time for each execution.
It is also important to keep in mind that System.nanoTime() might be relatively expensive in terms of execution time so we definitely should NOT put it inside the same loop as the measured function, unless all we want to measure is System.nanoTime() itself (been there, done that :-) ). So this is another reason why we need to call the desired function multiple times - to compensate System.nanoTime() overhead.
Another aspect is that we need a function that has some observable effects, e.g. returning a result that is accumulated and then printed out. Otherwise, the compiler could cut out the code that was meant to be measured (see: Could a compiler possibly optimize your benchmark away?).
Spanner
Another way to benchmark the code is to use a dedicated framework like Spanner. It's an Android-oriented, Caliper-like library which can make this task easier. Despite its alpha-ish state, it's quite usable and worth trying out.
Putting configuration matters aside, the benchmark function may look like this:
@Benchmark
fun addConstTest(reps: Long): Long {
var sum = 0L
for (i in 0 until reps) {
sum += addConst(i)
}
return sum
}
fun addConst(number: Long): Long {
return 5 + number
}
As you can see, the framework gives us the required repetitions count as a parameter and it's our job to actually run the code in a loop.
Side note: the current Spanner version (as of Feb 2, 2018) requires benchmark classes' and methods' modifiers to be exacly java.lang.reflect.Modifier.PUBLIC so you can't run final-by-default Kotlin code without additional open modifier. That's why I use my forked version with this behavior changed accordingly.
Spanner can also upload your benchmark results to https://microbenchmarks.appspot.com either anonymously or with a given API key.
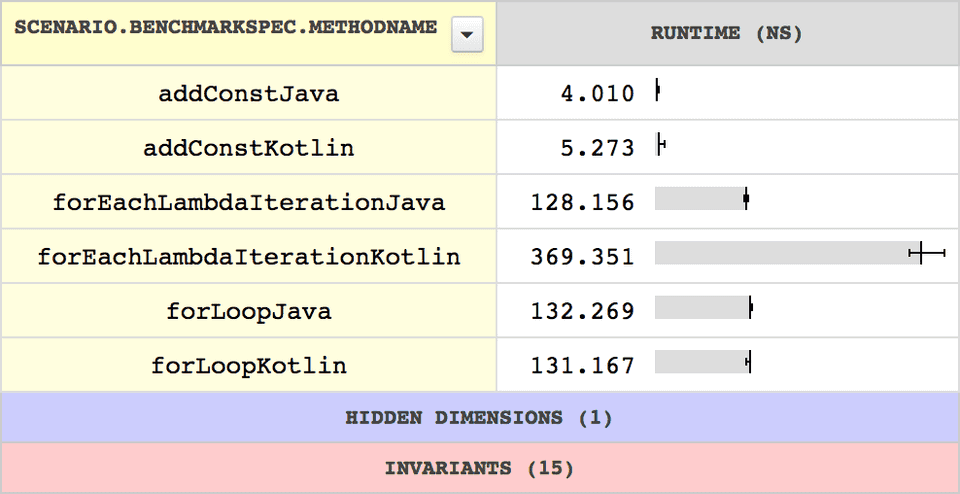
What could possibly go wrong?
It's very easy to get horribly misleading results, especially if you don't follow some rules when writing microbenchmarks. For example, this article by Julien Page shows how benchmarks may be optimized by the JVM so that the results become meaningless. A few criteria of a good benchmark have also been defined on this Caliper wiki page. And in this example Cédric Champeau proves why it's so important to use the right tool for measurements (like JMH).
Of course there are more issues that may happen, e.g.:
- garbage collection occurring during the measurements,
- temporarily increased CPU usage by other apps,
- JIT compiler making your code run faster each time,
- unavoidable CPU throttling.
Conclusion
Microbenchmarking is an interesting topic and I'm glad I could practice it myself and learn about it. As I've already mentioned, it's not something you should do on your daily basis, but still, I think it's worth reading about it and trying it out just to expand your horizons.