

AIOpenAI APILLMHIPPAZDRGDPR
5 min
OpenAI API Privacy Policies Explained

In my last blog post we have been tackling privacy when using ChatGPT Team and Enterprise plan. Today, we will discuss privacy for a product that will be used with a majority of OpenAI integrations. It will be OpenAI API. Compared to already described products it has the best privacy controls which I will dive into.
OpenAI Trust Portal
I have already mentioned it my other blog posts, but it’s worth to remind it. This is your go-to place for privacy and security when it comes to OpenAI. Upon this page, we can see that OpenAI is CCPA, GDPR, SOC2 and SOC3 compliant. You can download or request security papers from OpenAI. You can see the status of their infrastructure, all privacy policies, PII usage, data processing agreement or terms of service. It’s highly recommended to start your privacy journey here!
OpenAI Enterprise Privacy
Throughout your privacy journey, you should also visit Enterprise Privacy portal. It gives you more insight into how your data is used if you choose OpenAI API.
OpenAI API
To interact with OpenAI API you have to create an account (different than for ChatGPT, those are two different services) and attach payment. After it, you can start to interact with Playground or create API keys and integrate it with your app. The first thing to mention is that OpenAI API doesn’t train from business data:
We do not train on your business data (data from ChatGPT Team, ChatGPT Enterprise, or our API Platform)
The playground is simply a wrapper for API and it will not be used for training:
API and Playground requests will not be used to train our models.
So what about data storage?
OpenAI may securely retain API inputs and outputs for up to 30 days to provide the services and to identify abuse. After 30 days, API inputs and outputs are removed from our systems, unless we are legally required to retain them. You can also request zero data retention (ZDR) for eligible endpoints if you have a qualifying use-case. For details on data handling, visit our Platform Docs page.
Same as other OpenAI services we do have 30 days mentioned. What is new here, is ZDR - zero data retention. We are eligible for it when using API routes:
/v1/chat/completions (except image inputs), /v1/embeddings and /v1/completions. For /v1/audio/transcriptions, /v1/audio/translations, /v1/moderations ZDR is enabled by default. You can chat with support to enable ZDR in eligible endpoints.
What does it mean for us, software developers? When we are building our apps via eg. Langchain and using OpenAI embeddings (check the blog post of my colleague Paweł Polak on how to do it), we can steer out from data retention by OpenAI if using certain endpoints. This is important if we want to make our solution HIPPA-compliant. You can read more about it in the next paragraphs.
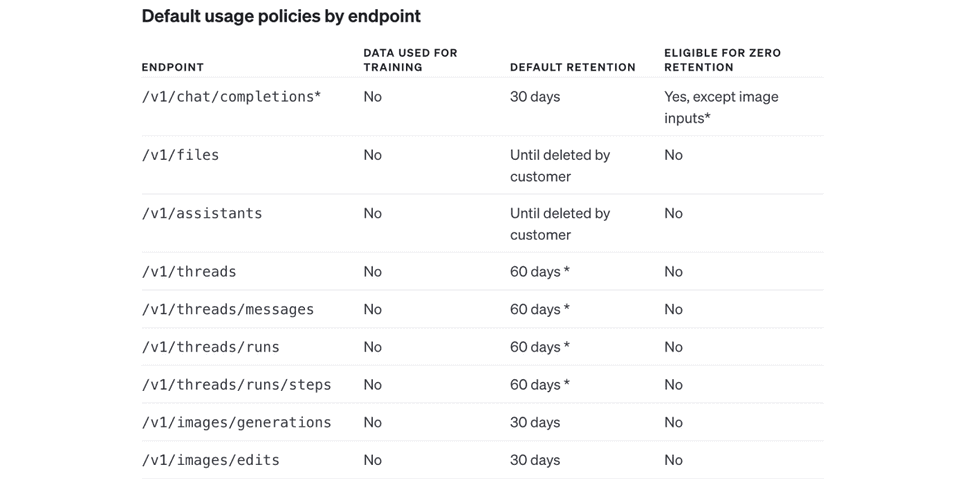
ZDR endpoints example. For full list please refer to OpenAI docs
Who can store the data if it is retained?
Our access to API business data stored on our systems is limited to (1) authorized employees that require access for engineering support, investigating potential platform abuse, and legal compliance and (2) specialized third-party contractors who are bound by confidentiality and security obligations, solely to review for abuse and misuse.
What is worth mentioning, if you upload files via /v1/files or using /v1/assistants, the default retention of data is:
Until deleted by customer
Regarding compliance, for GDPR OpenAI can execute:
Data Processing Addendum (DPA) with customers for their use of ChatGPT Team, ChatGPT Enterprise, and the API in support of their compliance with GDPR and other privacy laws
In case of SOC2:
Our API Platform has been audited and certified for SOC 2 Type 2 compliance
Apart from those, by having ZDR possibility we are eligible for HIPAA compliance:
We are able to sign Business Associate Agreements (BAA) in support of customers’ compliance with the Health Insurance Portability and Accountability Act (HIPAA). Please reach out to our sales team if you require a BAA.
There might be exceptions here for your use case though:
only endpoints that are eligible for zero retention are covered by the BAA. You can see a list of those endpoints.
With OpenAI API, you have also the possibility to finetune the model. What about data privacy in that case?
Yes, you can adapt certain models to specific tasks by fine-tuning them with your own prompt-completion pairs. Your fine-tuned models are for your use alone and never served to or shared with other customers or used to train other models. Data submitted to fine-tune a model is retained until the customer deletes the files.
What it means is that upon fine-tuning the model, your fine-tuned model is only for your use case and data remains there unless you delete it.
Last but not least, what is also important to mention is that
OpenAI encrypts all data at rest (AES-256) and in transit (TLS 1.2+), and uses strict access controls to limit who can access data.
As we can see, OpenAI API guarantees the best data control and privacy within all its offerings.
Read more blog posts about OpenAI Privacy Policy:
OpenAI ChatGPT Free & Plus Privacy Policies Explained